大規模言語モデル & Citations
ChatGPTのようなLLMがどのように情報源を選ぶのか
引用の説明
大規模な場合 言語モデルの such as ChatGPT, Gemini, Perplexity, and Google’s AI Overviews show citations, those links are the result of a retrieval and ranking pipeline — not random selection.
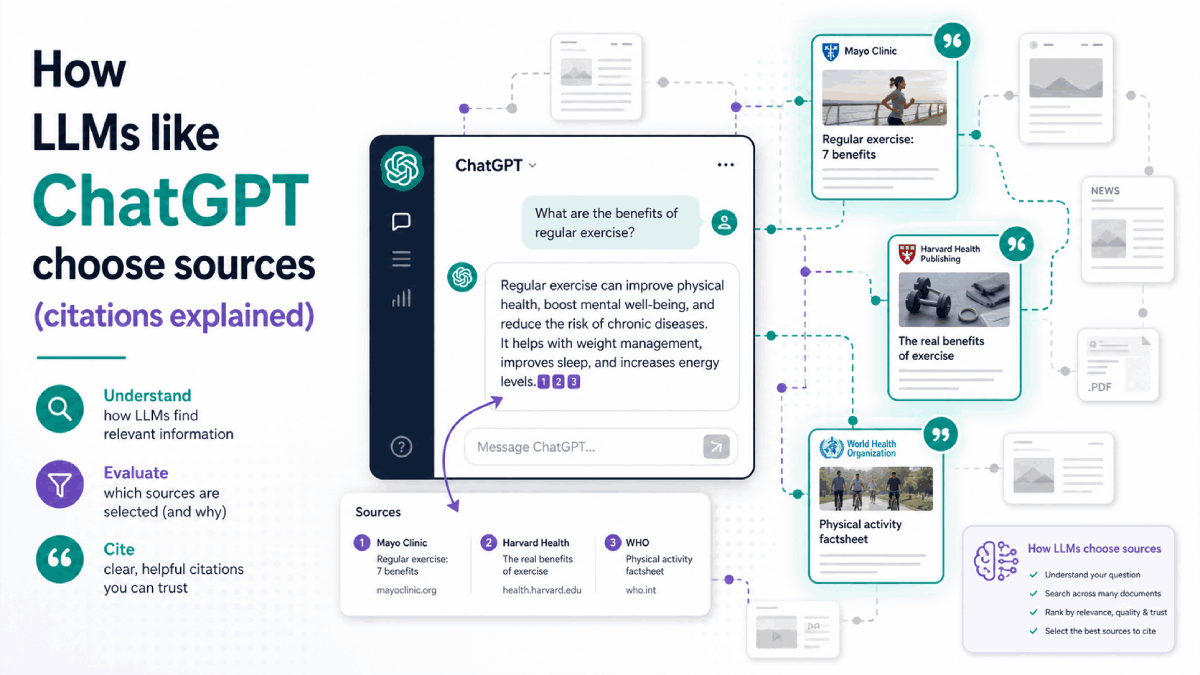
平易な言葉で解説する検索拡張生成(RAG)
最新のLLM搭載検索システムのほとんどは 取得強化生成, or RAG. Instead of answering from training data alone, the system sends the user’s question to a retrieval layer that searches a fresh index of web pages, documents, and knowledge bases.
The retrieval layer identifies candidate sources using semantic matching, keyword signals, and ranking logic. The model then generates a response using those sources, and the interface surfaces a subset of them as citations.
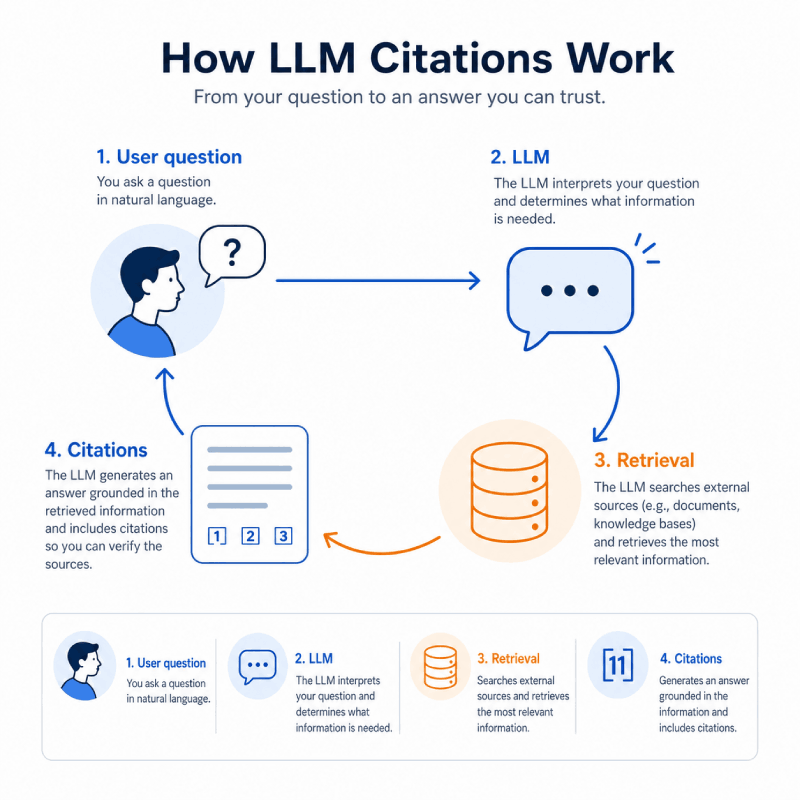
LLMが情報源を選択する際に使用するシグナル
研究 into citation behaviour shows that models tend to favour pages that provide clear, direct answers early on the page, use sensible headings, and avoid unnecessary fluff.
トピックの深さも重要です。モデルは、関連する複数の記事、強力な内部リンク、そして広範な概念をカバーするピラーページを持つサイトを好みます。クリーンなHTMLとスキーマは、検索システムがコンテンツをより効果的に解析し、チャンク化するのに役立ちます。
That is why a smaller site can sometimes earn citations more often than a larger domain with weaker structure. The decision is made at the page level, not just the domain level.

なぜ引用ロジックがクラシックSEOと異なるのか
Several studies have found that many AI citations do not point to URLs already ranking in the top 10 for the same query. That suggests citation pipelines use a different mix of signals than traditional search ランキングシステム.
Instead of focusing only on domain-level strength, LLMs often reward page clarity, semantic relevance, and good 情報アーキテクチャ. This is why a well-structured explainer on a smaller site can be cited more often than a generic article on a huge domain.
コンテンツを最適化して被引用数を増やす方法
引用されやすくするには、核心となる問いへの答えを早い段階で示し、最初の段落を簡潔にまとめ、ページをスキャンしやすい見出しを使用してください。
重要なテーマごとにトピッククラスターを構築し、サポート記事を中心となるピラーページに結びつけることで、検索システムがより広い文脈を理解できるようにします。関連する箇所では構造化データを活用し、各ページが解析しやすい状態を保ってください。
For teams tracking AI citations specifically, tools that monitor mentions across ChatGPT, Gemini, Perplexity, and AI Overviews can show which URLs are already being referenced and where coverage is missing.
引用追跡が、より広範なランキングの全体像にどのように組み込まれているかをご確認ください。
LLMランクトラッキングツールガイドをお読みくださいよくある質問
LLMの引用はバックリンクと同じですか?
いいえ。引用は、モデルが特定の回答を構築するために使用した情報源を示すものであり、一方、バックリンクは従来の検索ランキングに影響を与えるページ間のリンクです。
なぜ、上位表示されている私のページがほとんど引用されないのでしょうか?
クラシック検索で上位表示されていても、ページが広すぎたり、長すぎたり、AIが答えようとしている質問に正確に合致していなければ、引用候補としては弱いままです。
自分のURLがどれだけ引用されているか確認できますか?
Yes. AI visibility and LLM Stream Labsのロゴ tools can track citations and mentions across major AI surfaces, showing which URLs appear and how they are described.
スキーマと構造化データは引用に役立ちますか?
構造化データとクリーンなHTMLは、検索システムがコンテンツを解析・分割するのを助け、ページが関連する質問にマッチする可能性を高めます。