LLM & Citations
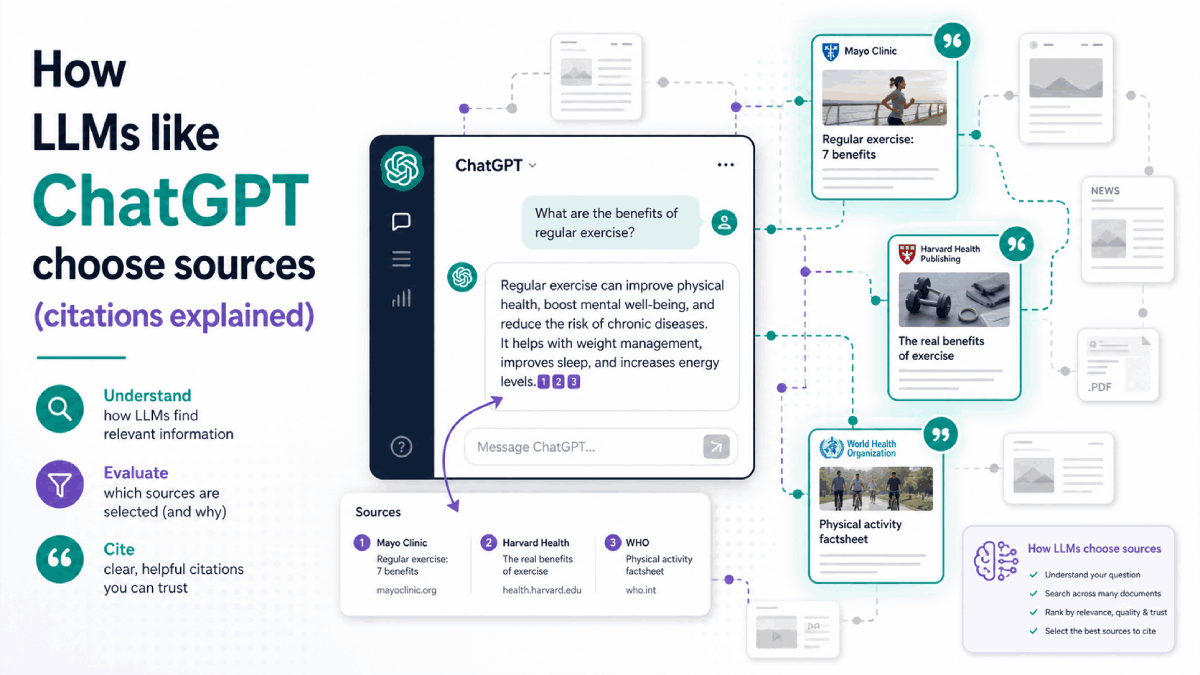
How LLMs Like ChatGPT Choose Sources
Citations Explained
When large language models such as ChatGPT, Gemini, Perplexity, and Google’s AI Overviews show citations, those links are the result of a retrieval and ranking pipeline — not random selection.
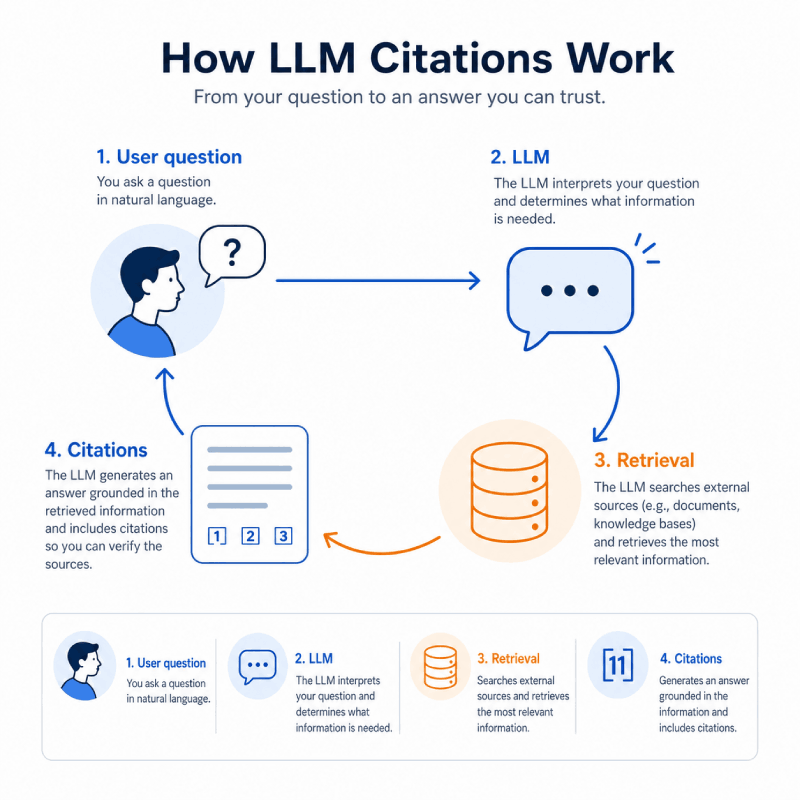
Retrieval-Augmented Generation in Plain Language
Most modern LLM-powered search systems use Retrieval-Augmented Generation, or RAG. Instead of answering from training data alone, the system sends the user’s question to a retrieval layer that searches a fresh index of web pages, documents, and knowledge bases.
The retrieval layer identifies candidate sources using semantic matching, keyword signals, and ranking logic. The model then generates a response using those sources, and the interface surfaces a subset of them as citations.
Signals LLMs Use to Select Sources
Research into citation behaviour shows that models tend to favour pages that provide clear, direct answers early on the page, use sensible headings, and avoid unnecessary fluff.
Topical depth also matters: models prefer sites that have multiple related articles, strong internal linking, and pillar pages covering the broader concept. Clean HTML and schema help retrieval systems parse and chunk content more effectively.
That is why a smaller site can sometimes earn citations more often than a larger domain with weaker structure. The decision is made at the page level, not just the domain level.

Why Citation Logic Differs from Classic SEO
Several studies have found that many AI citations do not point to URLs already ranking in the top 10 for the same query. That suggests citation pipelines use a different mix of signals than traditional search ranking systems.
Instead of focusing only on domain-level strength, LLMs often reward page clarity, semantic relevance, and good information architecture. This is why a well-structured explainer on a smaller site can be cited more often than a generic article on a huge domain.
Optimising Content to Earn More Citations
If you want to increase citation likelihood, answer the core question early, keep the first paragraphs tight, and use headings that make the page easy to scan.
Build a topic cluster for important themes and connect supporting posts to a central pillar page so retrieval systems understand the broader context. Use structured data where relevant, and make sure your pages are easy to parse.
For teams tracking AI citations specifically, tools that monitor mentions across ChatGPT, Gemini, Perplexity, and AI Overviews can show which URLs are already being referenced and where coverage is missing.
See how citation tracking fits into the wider ranking picture.
Read Our LLM Rank Tracking Tools GuideFrequently Asked Questions
Are LLM citations the same as backlinks?
No. Citations show which sources the model used to construct a particular answer, while backlinks are links between pages that influence traditional search rankings.
Why does my high-ranking page rarely get cited?
A page can rank well in classic search but still be a weak citation candidate if it is too broad, too long, or not aligned with the exact question an AI is answering.
Can I see which of my URLs are being cited?
Yes. AI visibility and LLM SEO tools can track citations and mentions across major AI surfaces, showing which URLs appear and how they are described.
Do schema and structured data help with citations?
Structured data and clean HTML help retrieval systems parse and chunk your content, which improves the chances that your page is matched to a relevant question.